Pim van den Berg
2015-01-01 11:20:15 UTC
Hi,
Since a couple of days I switched from bcache to lvmcache, running a
Linux 3.17.7 kernel. I was surprised that it was so easy to setup
lvmcache compared to bcache. :)
The system is a hypervisor and NFS-server. The LV that is used by the
NFS-server is 1TB, 35GB SSD cache is attached (1GB metadata). One of the
VMs runs a collectd (http://collectd.org/) server, which reads/writes a
lot of RRD files via NFS on the LV that uses lvmcache.
My experience with bcache was that the RRD files were always in the SSD
cache, because they were used so often, which was great! With bcache in
writethrough mode the collectd VM had an average of 8-10% Wait-IO,
because it had to wait until writes were written to the HDD. bcache in
writeback mode resulted in ~1% Wait-IO on the VM. The writeback cache
made writes very fast.
Now I switched to lvmcache. This is the output of dmsetup status:
0 2147483648 cache 8 2246/262144 128 135644/573440 366608 166900 7866816
295290 0 127321 0 1 writeback 2 migration_threshold 2048 mq 10
random_threshold 4 sequential_threshold 512 discard_promote_adjustment 1
read_promote_adjustment 0 write_promote_adjustment 0
As you can see I set read_promote_adjustment and
write_promote_adjustment to 0.
I created a collectd plugin to monitor the lvmcache usage:
https://github.com/pommi/collectd-lvmcache
Here are the results of a 2 hour time-span:
Loading Image...
Loading Image...
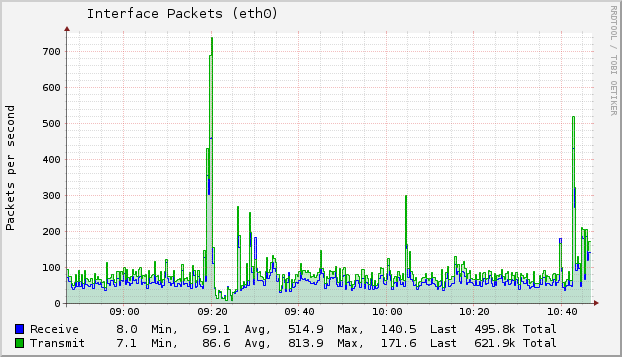
The 2nd link shows you that there are many "Write hits". You can almost
1-on-1 map these to this graph, which shows the eth0 network packets
(NFS traffic) on the collectd VM:
Loading Image...
So I think the conclusion is that the lvmcache writeback is used quite
well for caching the collectd RRDs.
But... when I look at the CPU usage of the VM there is 8-10% Wait-IO
(this also matches the 2 graphs mentioned above almost 1-on-1):
Loading Image...
This is equal to having no SSD cache at all or bcache in writethrough
mode. I was expecting ~1% Wait-IO.
How can this be explained?
writeback mode still wait for its data to be written to the HDD? Does
"Write hits" mean something different? Is "dmsetup status" giving me
wrong information? Or do I still have to set some lvmcache settings to
make this work as expected?
Since a couple of days I switched from bcache to lvmcache, running a
Linux 3.17.7 kernel. I was surprised that it was so easy to setup
lvmcache compared to bcache. :)
The system is a hypervisor and NFS-server. The LV that is used by the
NFS-server is 1TB, 35GB SSD cache is attached (1GB metadata). One of the
VMs runs a collectd (http://collectd.org/) server, which reads/writes a
lot of RRD files via NFS on the LV that uses lvmcache.
My experience with bcache was that the RRD files were always in the SSD
cache, because they were used so often, which was great! With bcache in
writethrough mode the collectd VM had an average of 8-10% Wait-IO,
because it had to wait until writes were written to the HDD. bcache in
writeback mode resulted in ~1% Wait-IO on the VM. The writeback cache
made writes very fast.
Now I switched to lvmcache. This is the output of dmsetup status:
0 2147483648 cache 8 2246/262144 128 135644/573440 366608 166900 7866816
295290 0 127321 0 1 writeback 2 migration_threshold 2048 mq 10
random_threshold 4 sequential_threshold 512 discard_promote_adjustment 1
read_promote_adjustment 0 write_promote_adjustment 0
As you can see I set read_promote_adjustment and
write_promote_adjustment to 0.
I created a collectd plugin to monitor the lvmcache usage:
https://github.com/pommi/collectd-lvmcache
Here are the results of a 2 hour time-span:
Loading Image...
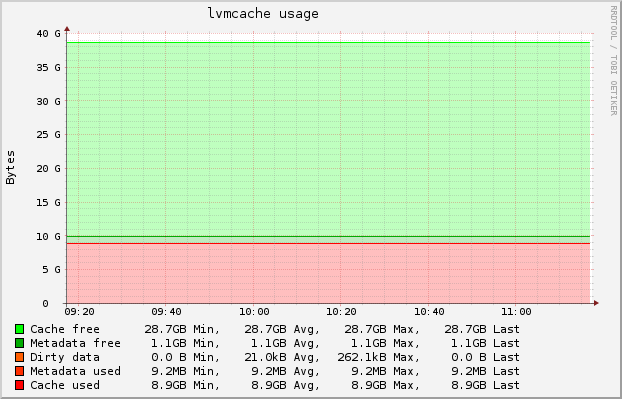
Loading Image...
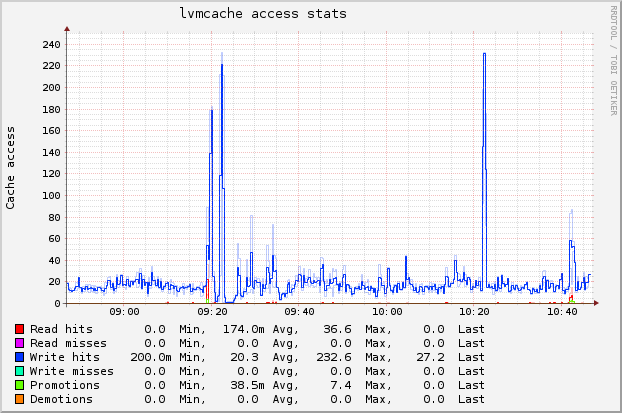
The 2nd link shows you that there are many "Write hits". You can almost
1-on-1 map these to this graph, which shows the eth0 network packets
(NFS traffic) on the collectd VM:
Loading Image...
So I think the conclusion is that the lvmcache writeback is used quite
well for caching the collectd RRDs.
But... when I look at the CPU usage of the VM there is 8-10% Wait-IO
(this also matches the 2 graphs mentioned above almost 1-on-1):
Loading Image...
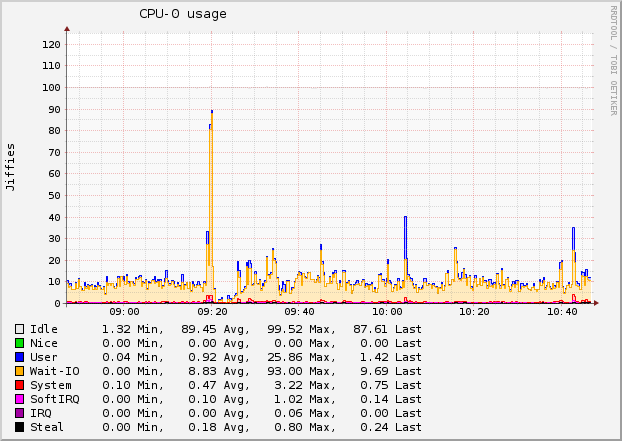
This is equal to having no SSD cache at all or bcache in writethrough
mode. I was expecting ~1% Wait-IO.
How can this be explained?
From the stats its clear that the pattern of "Network Packets", being
NFS traffic, matches the lvmcache "Write hits" pattern. Does lvmcache inwriteback mode still wait for its data to be written to the HDD? Does
"Write hits" mean something different? Is "dmsetup status" giving me
wrong information? Or do I still have to set some lvmcache settings to
make this work as expected?
--
Regards,
Pim
Regards,
Pim