Roy Sigurd Karlsbakk
2017-02-11 08:59:02 UTC
Hi all
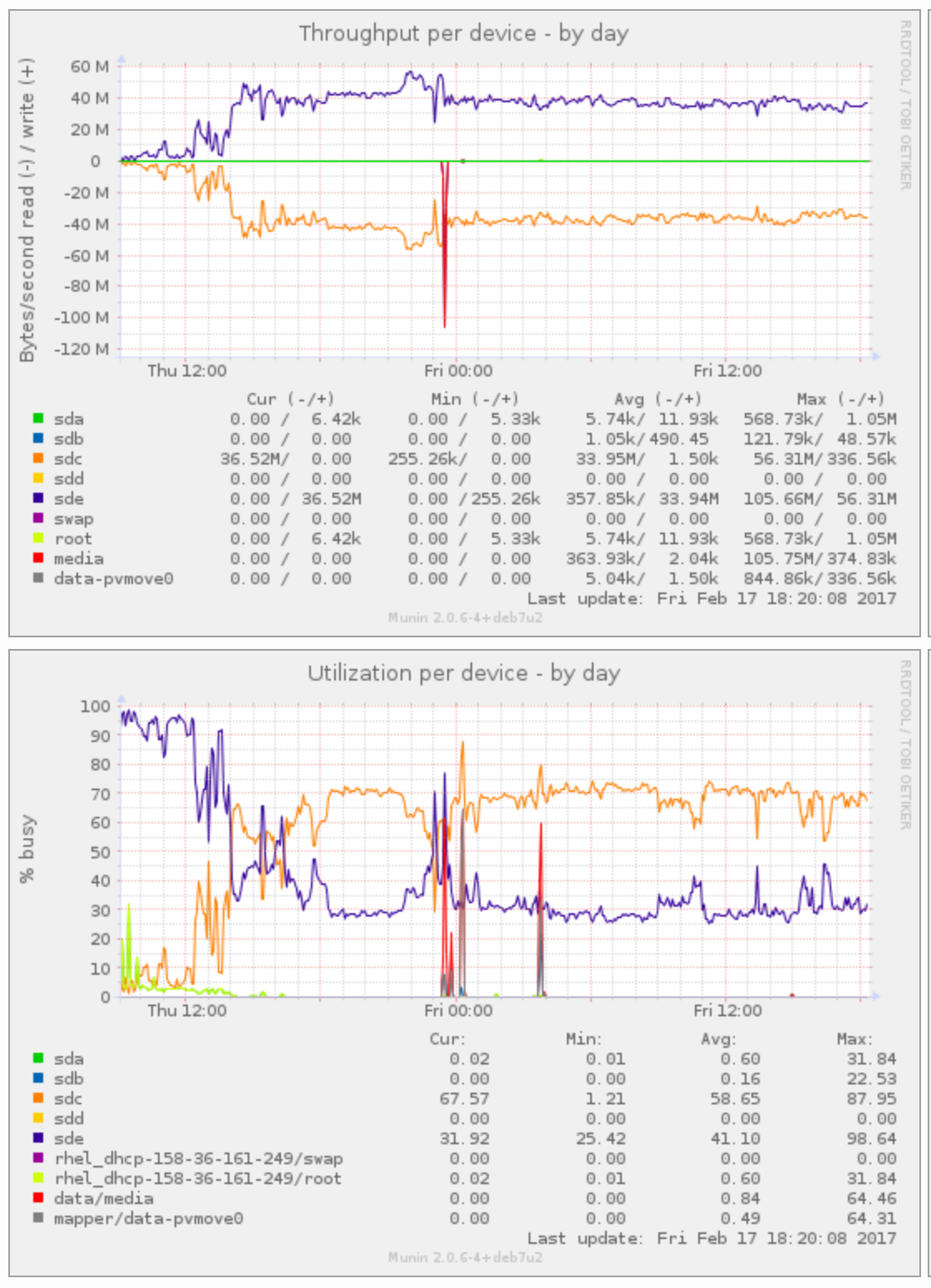
I'm doing pvmove of some rather large volumes from a Dell Equallogic system to Dell Compellent. Both are connected on iSCSI to vmware and the guest OS seems to do this well, but it's slow. I get around 50MB/s at most, even though the Equallogic is connected at 4x1Gbps and the Compellent is on 10Gbps. Without multipath, this should give me 100MB/s or so, but then, I get half of that. Interestingly, the "utilisation" reported by munin shows me a 100% in total of the two devices compared, as in Loading Image...
Any idea why this utilisation is so high, and what I can do to speed this thing up? I'm at a 14 days mark to move these 40TiB or so, and I'd like to reduce it if possible. The backend is obviously not a problem here.
Vennlig hilsen / Best regards
roy
--
Roy Sigurd Karlsbakk
(+47) 98013356
http://blogg.karlsbakk.net/
GPG Public key: http://karlsbakk.net/roysigurdkarlsbakk.pubkey.txt
--
Da mihi sis bubulae frustrum assae, solana tuberosa in modo Gallico fricta, ac quassum lactatum coagulatum crassum. Quod me nutrit me destruit.
I'm doing pvmove of some rather large volumes from a Dell Equallogic system to Dell Compellent. Both are connected on iSCSI to vmware and the guest OS seems to do this well, but it's slow. I get around 50MB/s at most, even though the Equallogic is connected at 4x1Gbps and the Compellent is on 10Gbps. Without multipath, this should give me 100MB/s or so, but then, I get half of that. Interestingly, the "utilisation" reported by munin shows me a 100% in total of the two devices compared, as in Loading Image...
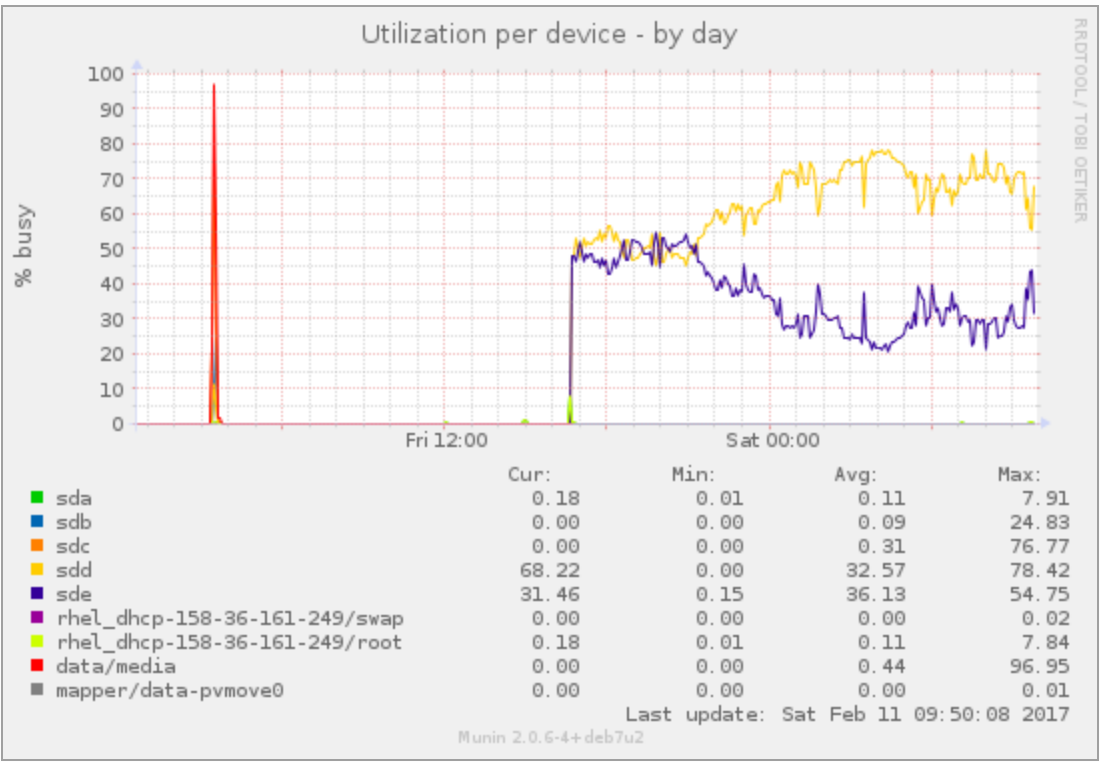
Any idea why this utilisation is so high, and what I can do to speed this thing up? I'm at a 14 days mark to move these 40TiB or so, and I'd like to reduce it if possible. The backend is obviously not a problem here.
Vennlig hilsen / Best regards
roy
--
Roy Sigurd Karlsbakk
(+47) 98013356
http://blogg.karlsbakk.net/
GPG Public key: http://karlsbakk.net/roysigurdkarlsbakk.pubkey.txt
--
Da mihi sis bubulae frustrum assae, solana tuberosa in modo Gallico fricta, ac quassum lactatum coagulatum crassum. Quod me nutrit me destruit.